You're Doing Interfaces Wrong
Interfaces are everywhere, but still we have tight coupling, and inflexibility. Dependency inversion is the answer.
You may have heard that NULLs don't work with Indexes. That's not true.

I had previously heard that NULLs don't get honored when selecting an index. More precisely, if IS NULL is a condition for a column in a SELECT statement, that column is ignored when choosing an index. The reason for this is apparently that NULL is considered such a common value that the optimiser assumes it is not specific enough to do the job.
I wanted to explore this further, and find out just how true that is, so I conducted a little experiment with the following table:
CREATE Table #temp
( [name] varchar(MAX)
, [deleted] bit NULL)
CREATE NONCLUSTERED INDEX IX_temp_deleted ON #temp (Deleted)I populated the table with some strings I had lying around, and set the deleted column values to the following ratios:
The total row count was 434.1 k rows.
To test the behavior of the index, I examined the execution plan for the below query:
SELECT COUNT(*) from #temp WHERE deleted IS NULL
This is unexpected - The plan seems to show we HAVE used the index!
Perhaps the fact we used a Count is key here - let's change that:
SELECT * from #temp WHERE deleted IS NULL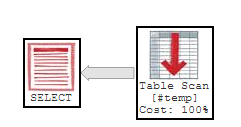
Aha - that looks more like what I was told would happen. A full table scan. But why was the index used on one query and not the other?
It seems SQL decided that we don't have to touch the table to work out the count - which can only mean that the index DOES record which records have NULLs.
This begs the question - does the index remember NULL values for this very specific purpose, and not use it for anything else? It seems unlikely!
If MS SQL gives us this concession, can we push it any further?
My first instinct was to perhaps use a <> 1 AND <> 0 condition in the WHERE clause to convince SQL into using the index - but this would be a mistake, as neither equality or inequality will return a NULL record.
Ordering is a function indexes help optimise. Does this still work if we have NULLs?
SELECT * from #temp ORDER BY Deleted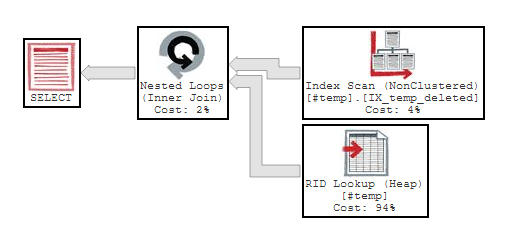
Yes, it did use the index to do the ordering. Unfortunately, because there are no other indexes on the table and no covering indexes, it is also doing a Heap lookup on the row-id... but this is the best option we could have hoped for.
If we can't use an index to optimise an IS NULL clause, perhaps using this ordering could offer some preformance benefit. For instance, the calling application could read row by row (i.e. not filling a datatable) and could stop reading once it got to a range it didn't want (i.e. the non-null values). After all, in ascending order, NULL would be at the beginning of the list. But if the app can do this - surely it's not such a stretch that SQL could do this on it's own?
Let's try putting an index hint on our Deleted IS NULL WHERE clause:
SELECT * FROM #temp
WHERE Deleted IS NULL
OPTION (TABLE HINT(#temp, INDEX(IX_temp_deleted)))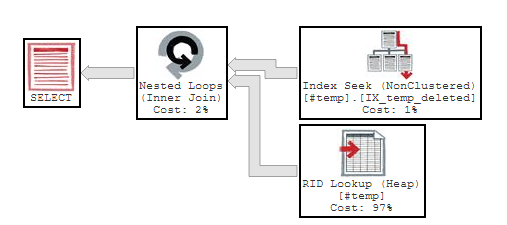
I wasn't anticipating this would work, but it did. However, although this looks like a healthier plan, it's not. In fact it executed 126144 logical reads compared to a mere 1463 reads when doing a full table scan. That's 8622% longer! For this plan to pay off, we would need to have far less NULL values than we do.
So, let's re-examine the opening assumption that checking for NULL makes indexes on that column useless. Perhaps the optimiser will choose the index if it is given a good reason to. To test this, I added an identity column (in fact, I added it a few tests ago, for those people who noticed this in the full query plans), and assigned all rows to be deleted = 0, but then 0.1% of rows to be Deleted = NULL:
UPDATE #temp SET Deleted = 0
UPDATE #temp SET Deleted = NULL WHERE (id % 1000) <= 1
ALTER INDEX IX_temp_deleted ON #temp REBUILDThen re-running our basic query, WITHOUT a query hint this is the resulting plan:
SELECT * from #temp WHERE deleted IS NULL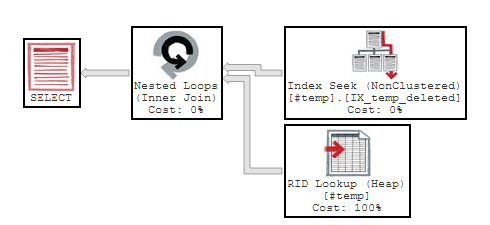
Well, that is interesting! The optimiser chose to use the index without a query hint.
In this case, this is the better plan, with a lower number of logical reads (only 438 compared to 1463 for a scan).
The issue with indexes and NULLs is not that the query optimiser just goes "Oh well, there's a null here, nothing I can do".
The query optimiser treats a NULL the same as any other value, and it is included in the indexes. The real issue is that NULL is such a common value that a table scan is often the better option. In short:
When I began writing this post it was going to be a very different article about how to trick the query optimiser into using a query - but as it turns out, no trickery is required!
All tests were done with SQL Server 13.0.4224.16